


Understanding and managing carbon footprints stand as pivotal actions for companies worldwide. A critical aspect of this process involves collecting and analyzing both primary and secondary data, each offering unique insights and bearing distinctive implications for carbon management strategies. This blog dives into the nuances of these data types, shedding light on their significance, methodologies for collection, and their respective roles in steering companies toward achieving net-zero targets.
Primary Data
What is primary data in carbon emissions measurement?
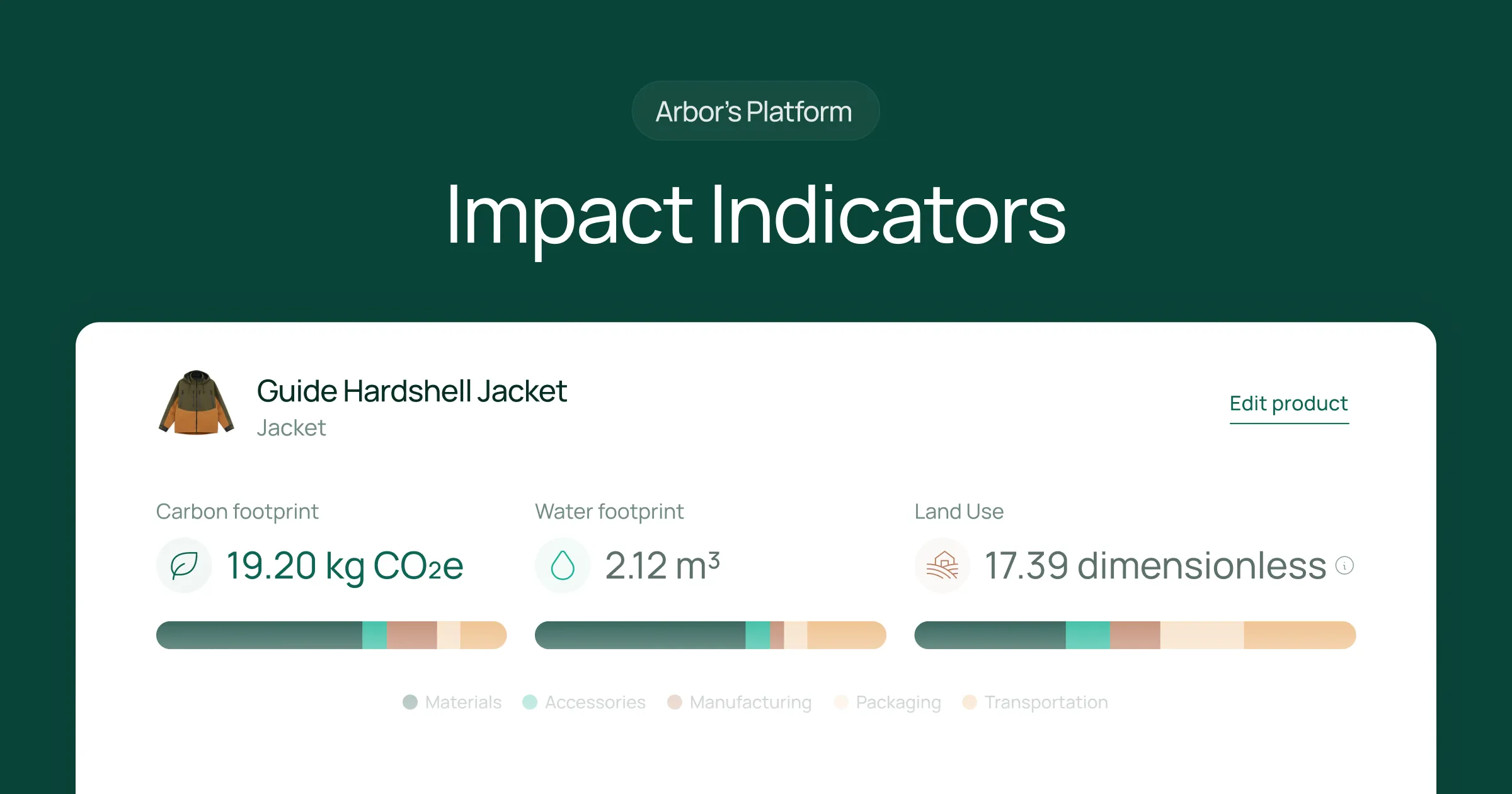
In carbon emissions measurement, primary data involves collecting information straight from the activities that occur within a company's value chain. This data is considered the gold standard because it is obtained directly from the source, offering undiluted insights into the business's operational impact on the environment. Primary data's direct relationship with a company's specific processes makes it indispensable for a precise assessment of carbon emissions, facilitating targeted strategies for reduction efforts.
What are examples or sources of primary data?
Primary data's richness comes from its variety, encompassing a wide array of operational activities:
- Production Processes: Direct emissions data from manufacturing or operational processes.
- Sales Transactions: Information on the sale of goods and services that can be correlated with emissions.
- Customer Interactions: Data gathered from consumer usage and feedback that can inform on product lifecycle emissions.
- Utility Bills and Meter Readings: Direct energy and water usage measurements, among others.
These examples underscore the depth and breadth of primary data, highlighting its integral role in carbon emissions assessment.
How do you collect primary data?
Collecting primary data is a multifaceted endeavour that necessitates a strategic approach. A widely used technique involves leveraging various tools and methodologies to capture data accurately:
- Engagement with Suppliers: Gathering energy data from suppliers and partners is crucial for understanding Scope 3 (indirect) emissions, which often account for a significant portion of a company's carbon footprint.
- Purchase Records: Tracking the procurement of goods and services can offer insights into supply chain emissions.
- Meter Readings and Utility Bills: Provide direct evidence of energy consumption, water use, and other utility data.
- Engineering Models and Direct Monitoring: These methods allow for the detailed mapping and measurement of emissions from specific processes.
What if you can’t get primary data to include in your carbon measurement?
In some instances, collecting primary data may not be feasible. In such cases, companies should not halt their carbon measurement efforts. Instead, leveraging secondary data becomes a viable alternative.
Secondary data from internationally recognized databases and publications can fill in the gaps. When the quality or specificity of secondary data falls short, proxy data—data from similar activities—can be customized or scaled to match the company’s operations better. This pragmatic approach ensures that companies can still make informed decisions toward their sustainability goals.
What are the advantages of primary data?
The utilization of primary data in carbon emissions measurement comes with significant advantages, including:
- Specificity to the Business: It offers an unrivalled level of detail and relevance to the company’s own operations.
- Benchmarking Capabilities: Enables the tracking of emissions over time and the assessment of reduction strategies’ effectiveness.
- Supplier Comparison: This tool facilitates accurate comparisons of GHG emissions between suppliers within the same value chain, aiding in sustainable supplier selection.
- Progress Tracking: Essential for setting and pursuing net-zero targets, as it allows businesses to measure and adapt their strategies based on accurate data.
What are the disadvantages of primary data?
Despite its benefits, the collection and application of primary data are not without challenges:
- Cost and Resource Intensity: The processes involved in gathering primary data can be costly and time-consuming.
- Data Verification Issues: Ensuring the accuracy and reliability of data, especially from external partners, can present difficulties.
- Complexity in Data Collection: The need for specialized tools or methodologies can complicate the process, requiring expertise that not all companies may have in-house.
Primary data is the cornerstone of accurate and effective carbon emissions measurement. Its direct correlation with a company's activities provides unparalleled insights into the environmental impact of operations, making it a powerful tool for sustainability. However, it requires a strategic approach to collection, analysis, and application, balanced with an understanding its limitations and the intelligent use of secondary data when necessary.
For companies aspiring to truthfully assess and reduce their carbon footprint, mastering the nuances of primary data collection and its integration into broader sustainability efforts is key.
Discover how Arbor can streamline your sustainability efforts and provide the tools to accurately measure and reduce your carbon footprint. Talk to our sales team today for a bespoke approach to becoming a net-zero company.
Secondary Data
What is secondary data in carbon emissions measurement?
Secondary data is a complementary data source. This data type is not gleaned directly from a company's specific actions or processes; instead, it is sourced from external datasets and research not intrinsically tied to the company's operations.
Secondary data serves as an invaluable resource, especially when direct, primary data collection is not feasible. It provides insights and benchmarks from broader industry contexts. Its incorporation into carbon measurement strategies allows for a more comprehensive understanding of a company’s environmental footprint, leveraging established knowledge and data points to inform and guide emissions reduction efforts.
What are examples or sources of secondary data?
Secondary data casts a wide net, capturing a diverse range of information crucial for carbon footprint analysis:
- Industry Benchmarks: Offering a comparative analysis of average sector-specific emissions.
- Published Research and Market Analysis: Providing insights into trends, innovations, and efficiency standards.
- Life Cycle Databases: Supplying quantified environmental impacts across product life cycles.
- Scientific Papers and Statistics: Contributing academic rigour and validated data to the emissions factors.
These sources act as the backbone for secondary data, enriching carbon emissions assessments with a depth of perspective and benchmarking capabilities that would be challenging to achieve through primary data alone.
Where does Arbor get secondary data from?
Arbor's accurate and comprehensive carbon footprint assessments are derived from our strategic sourcing of secondary data. By tapping into multiple internationally recognized sources, Arbor ensures that its analyses are both robust and reliable. This includes an array of databases and publications known for their authority and accuracy in the environmental domain:
- Trade Data and Energy Grid Information: Enabling a macro-view of emissions trends and dependencies.
- LCA Databases (e.g., Eco-invent, GABI): Providing detailed insights into the environmental impacts of various materials and processes.
- Transportation Routes Data: Offering a glimpse into emissions stemming from logistics and supply chain activities.
- Arbor’s Proprietary Emission Factor Data and LCA Studies: Further refining the understanding of specific emissions factors.
This curated selection of data sources empowers Arbor to give businesses the insights needed to navigate their sustainability journeys effectively.
What are the advantages of secondary data?
The strategic use of secondary data in carbon emissions measurement brings forth several distinct advantages:
- Accessibility: It enables analysis even when collecting primary data is challenging.
- Cost-Effectiveness: Particularly beneficial for covering broad areas of a company’s operations without the need for extensive primary data collection.
- Benchmarking and Hotspot Identification: Facilitates understanding the broader emissions landscape and identifying areas for targeted improvement.
- Scope 1, 2, and 3 Emissions Insights: This tool helps companies dissect their total emissions footprint, enabling strategic planning for reduction across all scopes.
These benefits make secondary data a crucial element in the toolkit for companies aiming to understand and mitigate their environmental impact.
What are the disadvantages of secondary data?
However, reliance on secondary data is not without its challenges:
- Potential for Misalignment: It may not accurately reflect the unique aspects of a company’s operations or capture the nuances of its specific emission reduction initiatives.
- Comparability Issues: Due to data granularity and context variances, it may be difficult to directly compare GHG emissions between suppliers in the same value chain.
- Limitation on Progress Monitoring: The generalized nature of the data might pose hurdles in tracking toward net-zero targets.
Despite these considerations, secondary data remains an indispensable resource in the environmental analyst's arsenal, providing valuable insights that enhance and complement the primary data collected directly by companies.
Understanding the strengths and limitations of secondary data is essential for companies embarking on their sustainability journeys. By leveraging this data, in conjunction with primary data wherever possible, businesses can gain a more comprehensive view of their carbon footprint, informing more effective strategies for reduction and management. Use Arbor’s platform to access key secondary data to supplement your carbon emissions measurement!
What is the difference between primary and secondary data?

When comparing primary and secondary data, both data types serve distinct, complementary roles in a company's sustainability efforts, each with its own set of advantages and limitations.
Primary Data is gathered directly from a company's operations, providing specific, undiluted insights into its environmental impact. Its direct sourcing from operational activities such as production processes, sales transactions, and utility usage makes it invaluable for precise carbon footprint assessments and targeted reduction strategies.
Its accuracy and specificity enable companies to perform detailed benchmarking, track emissions reduction progress effectively, and make accurate GHG comparisons between suppliers in the same value chain. However, collecting and applying primary data can be resource-intensive and costly, and it may involve complexities in data verification and collection.
Conversely, secondary data is not directly collected from a company's specific actions or processes but sourced from external datasets and research. This data complements primary data by providing broader context and industry benchmarks when direct data collection is not feasible. Examples include industry benchmarks, life cycle databases, and scientific papers, which enrich carbon emissions assessments with a broader perspective.
Secondary data's advantages lie in its accessibility and cost-effectiveness, allowing companies to cover broad operational areas and understand their emissions in relation to the wider industry. However, it may not always accurately reflect a company's unique operations or the nuances of its emission reduction initiatives, potentially complicating direct comparisons and tracking toward net-zero targets.
Primary data offers a superior level of detail specific to a company's operations, making it crucial for accurate emissions measurement and management. While potentially lacking in specificity, secondary data provides essential contextual information, enabling companies to position their efforts within the broader environmental landscape. Together, they form a comprehensive data foundation for companies to effectively assess, manage, and reduce their carbon footprint. Utilizing platforms like Arbor enables businesses to seamlessly integrate both data types into their sustainability strategies, ensuring a robust approach to achieving their environmental goals.
Summary
This deep dive into the intricacies of primary and secondary data in carbon emissions measurement highlights their importance for companies on the path to sustainability. Primary data, sourced directly from a company’s operational activities, provides untainted insights essential for precise carbon footprint assessments and formulation of targeted reduction strategies. It allows companies to benchmark, track emission reductions accurately, and compare GHG emissions effectively. However, it comes with challenges, including the cost, time, and complexity of collection and verification.
On the flip side, secondary data serves as a crucial complement, especially when primary data is inaccessible. It offers broader industry insights and benchmarks from external sources. Although it may lack the specificity of primary data and pose potential alignment issues, its accessibility and cost-effectiveness make it invaluable for understanding and mitigating environmental impacts.
Primary and secondary data furnish a rich, multifaceted view of a company's carbon footprint, enabling informed, strategic decisions toward achieving net-zero goals through platforms like Arbor. This blended approach underscores the necessity of leveraging both data types for a holistic sustainability strategy.
Talk to Arbor’s carbon experts to supplement our industry-leading secondary data to fill your data gaps.
Measure your carbon emissions with Arbor
Simple, easy carbon accounting.
FAQ on Primary & Secondary Data
How can primary and secondary data be combined to achieve more robust results in sustainability evaluations?
Integrating primary and secondary data offers a multifaceted approach to sustainability evaluations, enhancing the robustness and insightfulness of the results. Here’s how this combination works effectively:
Primary Data Collection: Primary data is gathered first-hand, tailored specifically to the evaluation’s objectives. This might include surveys, interviews, and direct observations, providing fresh, specific insights that are directly relevant to the project.
Secondary Data Utilization: Secondary data comprises information collected by other researchers or organizations, such as databases, previous studies, and official statistics. This data provides a broader context, helping to benchmark, compare, and enhance the interpretations made from primary data.
Enhanced Data Accuracy and Validity
- Cross-Verification: Using both types of data allows cross-checking of information. Primary data can be supported and validated with trends and patterns identified in secondary sources.
- Filling Gaps: Secondary data can fill in the gaps in primary data, especially in areas where collecting fresh data is constrained by resources or logistical issues.
Cost-Effectiveness and Efficiency
Combining both data types can be more cost-effective. Secondary data provides a cost-free or low-cost foundation, while primary data focuses on specific, strategic areas, minimizing unnecessary expenditure on data collection.
What are sources of primary and secondary data for LCA and carbon footprint assessments?
When conducting Life Cycle Assessments (LCA) and determining carbon footprints, accurate data is crucial. Let's explore the different sources of primary and secondary data that can help in these environmental assessments.
Primary Data Sources
Primary data consists of original information gathered first-hand. These sources are instrumental in generating high-precision data tailored for specific projects. Sources of primary data include:
- Operational Metrics from Production: Installing and utilizing monitoring equipment in manufacturing settings allows for the precise measurement of energy consumption, output rates, and other vital operational metrics. This data can be critical for assessing efficiency and environmental impact.
- Supplier Surveys: Engaging with suppliers to gather direct feedback and data can be instrumental. For instance, surveys may be used to verify the types of transportation used by suppliers, including the specifics of distances traveled and logistical details. This helps in understanding the supply chain's carbon footprint.
- Controlled Laboratory Tests: Conducting experiments in a controlled environment, such as a lab, allows researchers to isolate and measure specific variables like emission levels during chemical reactions. This type of data is essential for validating product safety and environmental compliance.
- User Feedback: Collecting data directly from the end-users through structured surveys sheds light on how products are used in real-world scenarios. This information can guide product improvements and indicate user behavior patterns for sustainability studies.
Ensuring the quality of primary data involves adhering to stringent protocols during the data collection phase, which enhances the accuracy and reliability of the information.
Secondary Data Sources
Secondary data, on the other hand, is collected from previously conducted studies and existing databases. It serves as an essential complement to primary data by providing broader context and supporting evidence. Prominent sources of secondary data include:
- Government Agencies: For instance, links to environmental and emissions data.
- Academic and Scientific Research: Publications in scientific journals offer peer-reviewed research findings.
- Industry Reports: These are often compiled by industry associations or specific sectors detailing relevant environmental data.
- International Organizations: Entities like the International Energy Agency provide comprehensive statistics and reports on global energy.
- Databases: Reputable databases like Ecoinvent supply vital data for various environmental impact assessments.
By effectively combining both primary and secondary data sources, researchers can undertake LCA and carbon footprint calculations that are both detailed and representative of wider environmental impacts. Each type of data plays a pivotal role in enriching the assessment, ensuring both depth and breadth in environmental studies.
What are examples of secondary data sources and how are they used in LCA and carbon footprint calculations?
Secondary data plays a crucial role in environmental research, specifically in Life Cycle Assessment (LCA) and calculating the carbon footprint of products or processes. This type of data is not originally collected by the researcher but sourced from other publications or databases. It's particularly useful in contexts where gathering firsthand data is too costly or logistically challenging.
Key Sources of Secondary Data:
- Government and Statistical Databases: These often provide comprehensive data on a wide range of factors related to environmental impacts, such as emissions from various industries.
- Industry-Specific Reports: Reports published by industry bodies can offer insights into average energy use and waste generation, which are pivotal for LCA.
- Academic and Scientific Literature: Research papers and articles frequently contain quantified findings on aspects like the lifecycle emissions of specific materials or products.
- Global and Regional Emission Databases: These databases compile emissions factors that are essential for carbon footprint calculations.
Usage in LCA and Carbon Footprint Assessments:
Secondary data is utilized extensively in the assessment of environmental impacts across a product’s lifecycle or in quantifying the carbon footprint of activities. Here’s how:
- Establishing Baselines: It helps in setting benchmark levels for comparison, like the average carbon dioxide output for producing a ton of steel.
- Filling Data Gaps: In many cases, primary data isn’t available for every aspect of the lifecycle. Secondary sources fill this void, providing a more complete assessment.
- Cost Reduction: Collecting primary data can be expensive and time-consuming. Using secondary data reduces both cost and effort significantly.
- Extending Reach: It enables researchers to include broader geographical and temporal dimensions in their studies without direct data collection.
Advantages and Challenges:
While secondary data is invaluable due to its accessibility and scope, relying on it comes with its drawbacks. It may not always precisely match the specific conditions of a study due to its generalized nature, posing challenges in terms of data relevancy and accuracy. Additionally, researchers have little control over the quality of secondary data, and it often requires validation or cross-referencing with other sources.
In conclusion, secondary data sources are foundational in conducting LCAs and estimating carbon footprints. They provide essential data that would otherwise be unattainable, contributing significantly to the fields of sustainable development and environmental protection. Nonetheless, careful consideration and handling are required to mitigate the limitations associated with its use.
What are the key differences between primary and secondary data in Life Cycle Assessment (LCA) and carbon footprint calculations?
Primary Data Overview
In Life Cycle Assessment (LCA) and carbon footprint calculations, primary data is data collected directly from the source. This method involves close-ended investigations and recordings about specific aspects of a product, process, or service. When researchers or analysts gather primary data, they are usually directly engaging with the elements involved, such as by assessing the inputs and outputs during the manufacturing phase or by measuring emission outputs during usage. Common sources of primary data include direct measurements, first-hand surveys, and observations within the operational premises.
Advantages of Primary Data:
- Specificity to the study’s needs
- Greater control over data quality
- Updated and highly relevant data
Secondary Data Overview
Secondary data, in contrast, is information that has already been gathered, processed, and published by other parties. This type of data is generally accessed through external sources such as academic journals, industry reports, government databases, and other digital publications. In LCA and carbon footprint methodologies, secondary data is incredibly useful, especially for baseline comparisons or when primary data gathering is too costly, time-consuming, or logistically impossible.
Advantages of Secondary Data:
- Cost-effective and time-saving
- Broad coverage can provide a more comprehensive view
- Accessible for comparing and contextualizing specific findings
Key Differences
- Source of Data: Primary data is directly collected by the researchers while secondary data is sourced from previously conducted studies and findings.
- Time and Cost: Gathering primary data can be time-intensive and expensive compared to using secondary data, which is usually readily accessible and less costly.
- Specificity and Relevance: Primary data is tailored to the specific needs of the research, making it highly relevant but narrowly focused. Secondary data offers broader context but may not align perfectly with the specific parameters of new research.
- Data Control: With primary data, the researcher has control over the quality and specificity of the information collected. This control is relinquished when relying on secondary data sources.
In summary, both primary and secondary data are crucial to LCA and carbon footprint calculations. The choice between them depends on the balance between need for precision, budget, time constraints, and the scope of the research. Efficient use of both types of data can often yield the most robust and reliable analyses.




.webp)
%20Directive.webp)


.webp)










%20Arbor.avif)





%20Arbor.avif)


.avif)





%20Arbor%20Canada.avif)

.avif)
%20Arbor.avif)
.avif)






_.avif)
.avif)
%20Arbor.avif)




%20Software%20and%20Tools.avif)





.avif)
.avif)




%20EU%20Regulation.avif)










.avif)


%20Arbor.avif)









_%20_%20Carbon%20101.avif)







.avif)









